Roll Your Own “Spotify Wrapped” with Arrow, R, and ListenBrainz
by Rakka • Tags:
View the original rendered R Notebook.
December comes again, and everybody is looking back at the past year. Seeing everyone’s Spotify Wrapped, I felt a little left out, since I don’t stream music. However, I have QuodLibet set up to scrobble listens to ListenBrainz, so let’s use Arrow and dplyr to generate our own retrospective. It won’t be exactly the same though, since I don’t have stuff like genre data easily available.
Setup
We’ll load all the libraries we’re using first.
library(arrow, warn.conflicts = FALSE)
library(dplyr, warn.conflicts = FALSE)
library(dbplyr, warn.conflicts = FALSE)
library(duckdb)
library(ggplot2)
Our dataset is stored as partitioned Parquet files, created using another script that grabs data from the ListenBrainz API.
ds <- open_dataset("listens", partitioning = c("year", "month"))
ds
FileSystemDataset with 92 Parquet files
listened_at: int64
artist_name: string
track_name: string
artist_mbids: list<element: string>
recording_mbid: string
release_mbid: string
year: int32
month: int32
Let’s get cracking!
Disclaimer: my R/dplyr is terrible, so apologies for any mistakes or unidiomatic patterns.
Total Rows
First, let’s get an idea of how big the dataset is.
ds %>% count() %>% collect()
| int n |
|---|
| 53405 |
This…isn’t big data. It’s not even medium data. It’s pretty small. So the tools we’re going to use here are massive overkill, but that’s okay.
Top Songs of the Year
First of all, let’s set up part of the query that we’re going to need a lot: filtering down to listens from the year 2021.
ds2021 <- ds %>%
filter(year == 2021) %>%
select(listened_at, artist_name, track_name, month)
And now a simple GROUP BY gets us top songs of the year:
ds2021 %>%
group_by(track_name) %>%
summarize(listens = n()) %>%
arrange(desc(listens)) %>%
head(25) %>%
collect()
| chr track_name | int listens |
|---|---|
| 夕日坂 | 400 |
| Tiny Stars | 228 |
| メルト (MikuV3 by Cillia) | 191 |
| キャットフード | 165 |
| ODDS&ENDS | 156 |
| 劣等上等 | 149 |
| ロミオとシンデレラ | 119 |
| Eternal Snow | 107 |
| 春はゆく | 105 |
| New Future | 103 |
| Myself | 102 |
| メルト (Otomachi Una by Cillia) | 90 |
| Yoru wo Kakeru (夜を駆ける / Run Through the Night) | 89 |
| 歌に形はないけれど (doriko) | 86 |
| I♥U | 83 |
| Eternal Snow (Diamond Dust mix) | 81 |
| 夢路 | 80 |
| 大喜 | 78 |
| 星屑ユートピア | 78 |
| 羞花 | 77 |
| Gimme×Gimme | 76 |
| 面影ワープ | 76 |
| 一百万个可能(翻唱:Christine Welch) | 74 |
| ふたつの影 | 72 |
| Returns | 71 |
Top Artists of the Year
Getting the top artists is also straightforward:
ds2021 %>%
group_by(artist_name) %>%
summarize(listens = n()) %>%
arrange(desc(listens)) %>%
head(25) %>%
collect()
| chr artist_name | int listens |
|---|---|
| 石进 | 994 |
| nano.RIPE | 460 |
| ヨルシカ | 413 |
| The National | 400 |
| Changin' My Life | 394 |
| doriko | 388 |
| ryo feat. 初音ミク | 281 |
| Yasunori Mitsuda | 233 |
| 澁谷かのん(CV.伊達さゆり)、唐可可(CV.Liyuu) | 228 |
| Kan Gao | 216 |
| TENMON (天門) | 212 |
| doriko feat.初音ミク | 201 |
| 音阙诗听 | 200 |
| 八王子P feat. 初音ミク | 193 |
| ryo (supercell) feat. 初音ミク | 156 |
| Tomoya Naka | 154 |
| こはならむ | 154 |
| RAISE A SUILEN | 152 |
| Spitz | 150 |
| 纯白, 花儿不哭 feat. 洛天依 | 137 |
| Yuki Kajiura | 135 |
| Poppin'Party | 133 |
| Aimer | 131 |
| RADWIMPS | 127 |
| K.D. | 123 |
Unfortunately, due to data quality, this isn’t perfect.
For instance, we have both “doriko” and “doriko feat.初音ミク”.
We can manually address this with case_when:
ds2021 %>%
mutate(
artist_name = case_when(
str_detect(artist_name, fixed("doriko")) ~ "doriko",
str_detect(artist_name, fixed("ryo")) ~ "ryo (supercell)",
str_detect(artist_name, fixed("supercell")) ~ "ryo (supercell)",
str_detect(artist_name, fixed("花たん")) ~ "Hanatan",
str_detect(artist_name, fixed("梶浦由記")) ~ "Yuki Kajiura",
str_detect(artist_name, fixed("音阙诗听")) ~ "音阙诗听",
TRUE ~ artist_name)
) %>%
group_by(artist_name) %>%
summarize(listens = n()) %>%
arrange(desc(listens)) %>%
head(25) %>%
collect()
| chr artist_name | int listens |
|---|---|
| 石进 | 994 |
| doriko | 667 |
| ryo (supercell) | 535 |
| nano.RIPE | 460 |
| 音阙诗听 | 417 |
| ヨルシカ | 413 |
| The National | 400 |
| Changin' My Life | 394 |
| Hanatan | 304 |
| Yasunori Mitsuda | 233 |
| 澁谷かのん(CV.伊達さゆり)、唐可可(CV.Liyuu) | 228 |
| Yuki Kajiura | 225 |
| Kan Gao | 216 |
| TENMON (天門) | 212 |
| 八王子P feat. 初音ミク | 193 |
| こはならむ | 154 |
| Tomoya Naka | 154 |
| RAISE A SUILEN | 152 |
| Spitz | 150 |
| 纯白, 花儿不哭 feat. 洛天依 | 137 |
| Poppin'Party | 133 |
| Aimer | 131 |
| RADWIMPS | 127 |
| K.D. | 123 |
| Belle | 120 |
This doesn’t scale too well, but it gets us what we’re after. I’m surprised 石进 beats out everyone else!
Top by Month
Now let’s dig down deeper. For this, we’ll need to bring out the big guns: window functions! Arrow itself as of this writing (the development version of v7.0.0) lacks direct support for them. However, that’s no problem: the whole point of Arrow is to facilitate painless, costless data exchange across systems, and so the Arrow R package can seamlessly send data to DuckDB for further analysis, without copying data!
ds2021 %>%
group_by(month) %>%
count(track_name) %>%
to_duckdb() %>%
mutate(rank = min_rank(desc(n))) %>%
slice_min(n = 3, order_by = rank) %>%
arrange(month, rank) %>%
collect()
| int month | chr track_name | dbl n | dbl rank |
|---|---|---|---|
| 1 | 星屑ユートピア | 35 | 1 |
| 1 | 月影とブランコ | 25 | 2 |
| 1 | 夢路 | 23 | 3 |
| 2 | ダブルラリアット [Double Bass Drum Remix 2021] (feat. 巡音ルカ) | 31 | 1 |
| 2 | キャットフード | 19 | 2 |
| 2 | 面影ワープ | 18 | 3 |
| 2 | 嘘月 | 18 | 3 |
| 3 | 劣等上等 | 86 | 1 |
| 3 | 花的微笑 | 29 | 2 |
| 3 | みんなみくみくにしてあげる♪ | 28 | 3 |
| 4 | メルト (MikuV3 by Cillia) | 102 | 1 |
| 4 | メルト (Otomachi Una by Cillia) | 31 | 2 |
| 4 | 劣等上等 | 28 | 3 |
| 4 | 羞花 | 28 | 3 |
| 5 | Myself | 37 | 1 |
| 5 | Heart Chrome | 30 | 2 |
| 5 | ODDS&ENDS | 30 | 2 |
| 6 | New Future | 24 | 1 |
| 6 | ODDS&ENDS | 21 | 2 |
| 6 | ふたつの影 | 21 | 2 |
| 6 | Myself | 21 | 2 |
| 7 | 春はゆく | 79 | 1 |
| 7 | 一百万个可能(翻唱:Christine Welch) | 64 | 2 |
| 7 | 寅时 | 43 | 3 |
| 8 | 夕日坂 | 71 | 1 |
| 8 | Tiny Stars | 71 | 1 |
| 8 | ODDS&ENDS | 38 | 3 |
| 8 | 中华缘木娘 (Chinese Yuanmu Girl) | 38 | 3 |
| 9 | 夕日坂 | 175 | 1 |
| 9 | Tiny Stars | 107 | 2 |
| 9 | ODDS&ENDS | 31 | 3 |
| 10 | 夕日坂 | 55 | 1 |
| 10 | キャットフード | 33 | 2 |
| 10 | Great Wide Unknown (Bonus Song) | 27 | 3 |
| 11 | 夕日坂 | 38 | 1 |
| 11 | 歌に形はないけれど | 33 | 2 |
| 11 | Tiny Stars | 21 | 3 |
| 12 | 夕日坂 | 27 | 1 |
| 12 | song for you(サニーピースver.) | 26 | 2 |
| 12 | 涙だけ / feat. IA* | 15 | 3 |
Just for fun, we can see the generated SQL too:
ds2021 %>%
group_by(month) %>%
count(track_name) %>%
to_duckdb() %>%
mutate(rank = min_rank(desc(n))) %>%
slice_min(n = 3, order_by = rank) %>%
arrange(month, rank) %>%
show_query()
<SQL>
SELECT "month", "track_name", "n", "rank"
FROM (SELECT "month", "track_name", "n", "rank", RANK() OVER (PARTITION BY "month" ORDER BY "rank") AS "q01"
FROM (SELECT "month", "track_name", "n", RANK() OVER (PARTITION BY "month" ORDER BY "n" DESC) AS "rank"
FROM "arrow_002") "q01") "q02"
WHERE ("q01" <= 3)
ORDER BY "month", "rank"
I’m…not certain that’s optimal, but I didn’t have to work it out by hand, so I won’t complain!
And we can do the same for artists:
ds2021 %>%
mutate(
artist_name = case_when(
str_detect(artist_name, fixed("doriko")) ~ "doriko",
str_detect(artist_name, fixed("ryo")) ~ "ryo (supercell)",
str_detect(artist_name, fixed("supercell")) ~ "ryo (supercell)",
str_detect(artist_name, fixed("花たん")) ~ "Hanatan",
str_detect(artist_name, fixed("梶浦由記")) ~ "Yuki Kajiura",
str_detect(artist_name, fixed("音阙诗听")) ~ "音阙诗听",
TRUE ~ artist_name)
) %>%
group_by(month) %>%
count(artist_name) %>%
to_duckdb() %>%
mutate(rank = min_rank(desc(n))) %>%
slice_min(n = 3, order_by = rank) %>%
arrange(month, rank) %>%
collect()
| int month | chr artist_name | dbl n | dbl rank |
|---|---|---|---|
| 1 | nano.RIPE | 156 | 1 |
| 1 | ヨルシカ | 102 | 2 |
| 1 | The National | 57 | 3 |
| 2 | nano.RIPE | 72 | 1 |
| 2 | ヨルシカ | 38 | 2 |
| 2 | 鬱P | 31 | 3 |
| 2 | 石进 | 31 | 3 |
| 3 | 石进 | 568 | 1 |
| 3 | RAISE A SUILEN | 82 | 2 |
| 3 | ヨルシカ | 68 | 3 |
| 4 | ryo (supercell) | 152 | 1 |
| 4 | 石进 | 98 | 2 |
| 4 | The National | 66 | 3 |
| 5 | Changin' My Life | 70 | 1 |
| 5 | ryo (supercell) | 63 | 2 |
| 5 | tilt-six | 53 | 3 |
| 6 | 石进 | 108 | 1 |
| 6 | Changin' My Life | 73 | 2 |
| 6 | ryo (supercell) | 66 | 3 |
| 7 | 音阙诗听 | 101 | 1 |
| 7 | Aimer | 87 | 2 |
| 7 | Tomoya Naka | 82 | 3 |
| 8 | doriko | 96 | 1 |
| 8 | ryo (supercell) | 89 | 2 |
| 8 | 纯白, 花儿不哭 feat. 洛天依 | 84 | 3 |
| 9 | doriko | 193 | 1 |
| 9 | 石进 | 123 | 2 |
| 9 | 澁谷かのん(CV.伊達さゆり)、唐可可(CV.Liyuu) | 107 | 3 |
| 10 | doriko | 122 | 1 |
| 10 | Kan Gao | 91 | 2 |
| 10 | Hanatan | 77 | 3 |
| 11 | まらしぃ | 86 | 1 |
| 11 | doriko | 70 | 2 |
| 11 | K.D. | 43 | 3 |
| 12 | doriko | 32 | 1 |
| 12 | サニーピース | 26 | 2 |
| 12 | Yuki Kajiura | 15 | 3 |
| 12 | 傘村トータ | 15 | 3 |
Fun!
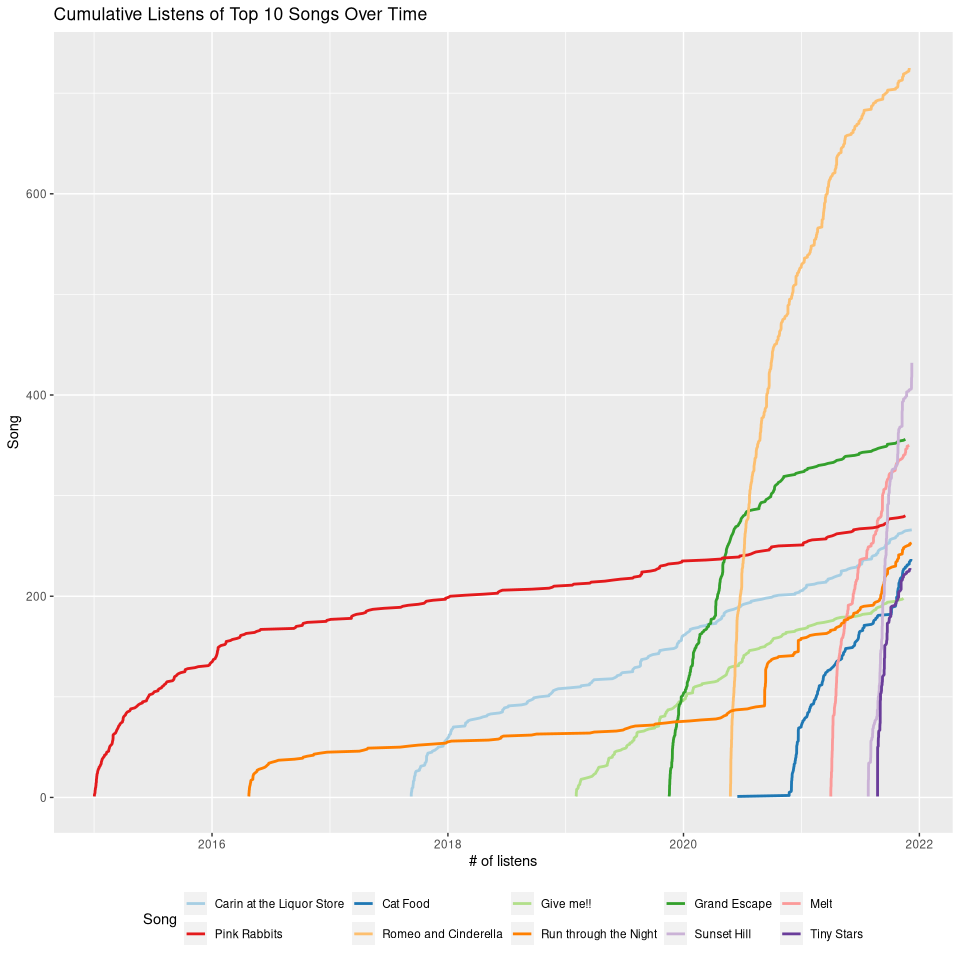
Listens Over Time
Finally, let’s look at all our data, not just 2021. We’ll take the 10 most-listened songs, then plot how the listen count has accumulated over time.
fixed_tracks <- ds %>%
mutate(track_name = case_when(
str_detect(track_name, fixed("Yoru wo Kakeru")) ~ "Run through the Night",
str_detect(track_name, fixed("夜を駆ける")) ~ "Run through the Night",
str_detect(track_name, fixed("Grand Escape")) ~ "Grand Escape",
str_detect(track_name, fixed("メルト")) ~ "Melt",
str_detect(track_name, fixed("キャットフード")) ~ "Cat Food",
str_detect(track_name, fixed("ロミオとシンデレラ")) ~ "Romeo and Cinderella",
str_detect(track_name, fixed("夕日坂")) ~ "Sunset Hill",
TRUE ~ track_name
))
top10 <- fixed_tracks %>%
group_by(track_name) %>%
summarize(listens = n()) %>%
arrange(desc(listens)) %>%
head(10) %>%
collect()
top10
| chr track_name | int listens |
|---|---|
| Romeo and Cinderella | 725 |
| Sunset Hill | 432 |
| Grand Escape | 356 |
| Melt | 350 |
| Pink Rabbits | 280 |
| Carin at the Liquor Store | 266 |
| Run through the Night | 253 |
| Cat Food | 237 |
| Tiny Stars | 228 |
| Give me!! | 198 |
Next, we’ll use a join to filter our original dataset, keeping only the top 10 songs:
top10_over_time <- fixed_tracks %>%
select(listened_at, track_name) %>%
inner_join(top10) %>%
select(listened_at, track_name)
top10_over_time %>% collect()
| int listened_at | chr track_name |
|---|---|
| 1422810718 | Pink Rabbits |
| 1422844759 | Pink Rabbits |
| 1423278815 | Pink Rabbits |
| 1423358788 | Pink Rabbits |
| 1423447698 | Pink Rabbits |
| 1423958002 | Pink Rabbits |
| 1423972881 | Pink Rabbits |
| 1424052333 | Pink Rabbits |
| 1424143077 | Pink Rabbits |
| 1424198856 | Pink Rabbits |
| (data trimmed…) | |
Finally, we’ll swap over to DuckDB and compute a cumulative sum:
cumulative_listens <- top10_over_time %>%
select(listened_at, track_name) %>%
# Get something to cumsum
mutate(n = 1) %>%
group_by(track_name) %>%
to_duckdb() %>%
arrange(listened_at) %>%
mutate(listens = cumsum(n)) %>%
to_arrow() %>%
mutate(listened_at = cast(listened_at, timestamp("s"))) %>%
arrange(listened_at) %>%
collect()
cumulative_listens %>% head(10)
| S3: POSIXct listened_at | chr track_name | dbl n | dbl listens |
|---|---|---|---|
| 2015-01-01 12:53:58 | Pink Rabbits | 1 | 1 |
| 2015-01-01 13:46:05 | Pink Rabbits | 1 | 2 |
| 2015-01-01 19:56:49 | Pink Rabbits | 1 | 3 |
| 2015-01-02 23:41:07 | Pink Rabbits | 1 | 4 |
| 2015-01-03 11:09:45 | Pink Rabbits | 1 | 5 |
| 2015-01-03 12:52:05 | Pink Rabbits | 1 | 6 |
| 2015-01-03 18:08:59 | Pink Rabbits | 1 | 7 |
| 2015-01-04 11:16:51 | Pink Rabbits | 1 | 8 |
| 2015-01-04 11:50:30 | Pink Rabbits | 1 | 9 |
| 2015-01-05 16:17:46 | Pink Rabbits | 1 | 10 |
(We send the data back to Arrow to convert to timestamps since the DuckDB integration gives a type error if we do it beforehand.)
ggplot(data = cumulative_listens, aes(x = listened_at, y = listens, group = track_name, colour = track_name)) +
ggtitle("Cumulative Listens of Top 10 Songs Over Time") +
xlab("# of listens") +
ylab("Song") +
labs(colour = "Song") +
geom_line(size = 1) +
scale_color_brewer(palette = "Paired") +
theme(legend.position = "bottom", legend.box = "vertical") +
guides(colour = guide_legend(nrow = 2, byrow = TRUE))
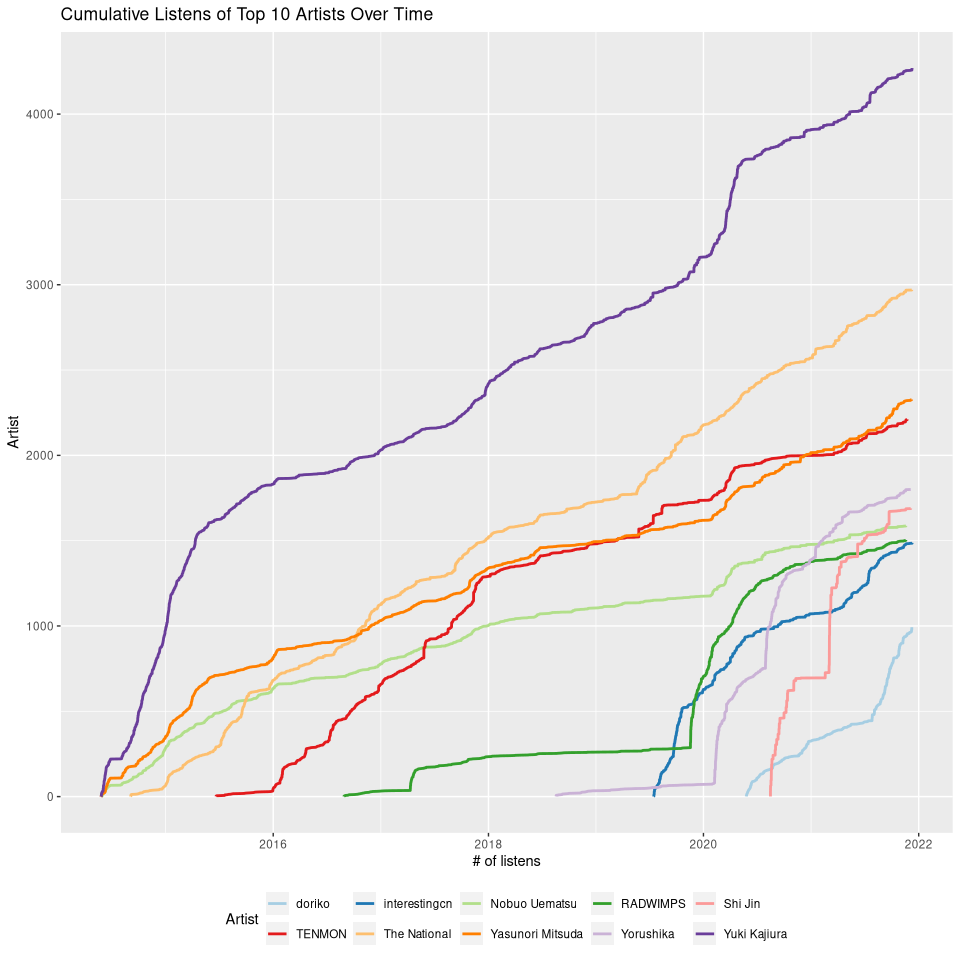
We can do the same for artists.
fixed_artists <- ds %>%
mutate(
artist_name = case_when(
str_detect(artist_name, fixed("doriko")) ~ "doriko",
str_detect(artist_name, fixed("ryo")) ~ "ryo (supercell)",
str_detect(artist_name, fixed("supercell")) ~ "ryo (supercell)",
str_detect(artist_name, fixed("花たん")) ~ "Hanatan",
str_detect(artist_name, fixed("梶浦由記")) ~ "Yuki Kajiura",
str_detect(artist_name, fixed("Kalafina")) ~ "Yuki Kajiura",
str_detect(artist_name, fixed("FictionJunction")) ~ "Yuki Kajiura",
str_detect(artist_name, fixed("音阙诗听")) ~ "interestingcn",
str_detect(artist_name, fixed("石进")) ~ "Shi Jin",
str_detect(artist_name, fixed("光田康典")) ~ "Yasunori Mitsuda",
str_detect(artist_name, fixed("Yasunori Mitsuda, Millenial Fair")) ~ "Yasunori Mitsuda",
str_detect(artist_name, fixed("植松伸夫")) ~ "Nobuo Uematsu",
str_detect(artist_name, fixed("Nobuo Uematsu / Ririko Yamabuki")) ~ "Nobuo Uematsu",
str_detect(artist_name, fixed("スピッツ")) ~ "Spitz",
str_detect(artist_name, fixed("天門")) ~ "TENMON",
str_detect(artist_name, fixed("ヨルシカ")) ~ "Yorushika",
str_detect(artist_name, fixed("Dj Okawari, Emily Styler")) ~ "DJ Okawari",
TRUE ~ artist_name)
)
top10_artists <- fixed_artists %>%
group_by(artist_name) %>%
summarize(listens = n()) %>%
arrange(desc(listens)) %>%
head(10) %>%
collect()
top10_artists
| chr artist_name | int listens |
|---|---|
| Yuki Kajiura | 4270 |
| The National | 2970 |
| Yasunori Mitsuda | 2327 |
| TENMON | 2211 |
| Yorushika | 1800 |
| Shi Jin | 1689 |
| Nobuo Uematsu | 1587 |
| RADWIMPS | 1504 |
| interestingcn | 1488 |
| doriko | 993 |
top10_artists_over_time <- fixed_artists %>%
select(listened_at, artist_name) %>%
inner_join(top10_artists) %>%
select(listened_at, artist_name)
cumulative_artists <- top10_artists_over_time %>%
select(listened_at, artist_name) %>%
mutate(n = 1) %>%
group_by(artist_name) %>%
to_duckdb() %>%
arrange(listened_at) %>%
mutate(listens = cumsum(n)) %>%
to_arrow() %>%
mutate(listened_at = cast(listened_at, timestamp("s"))) %>%
arrange(listened_at) %>%
collect()
cumulative_artists %>% head(10)
| S3: POSIXct listened_at | chr artist_name | dbl n | dbl listens |
|---|---|---|---|
| 2014-05-26 12:09:38 | Yuki Kajiura | 1 | 1 |
| 2014-05-26 12:23:06 | Yasunori Mitsuda | 1 | 1 |
| 2014-05-26 12:28:42 | Yasunori Mitsuda | 1 | 2 |
| 2014-05-26 12:35:01 | Yuki Kajiura | 1 | 2 |
| 2014-05-27 11:20:10 | Yuki Kajiura | 1 | 3 |
| 2014-05-27 11:30:44 | Yuki Kajiura | 1 | 4 |
| 2014-05-27 11:43:46 | Yasunori Mitsuda | 1 | 3 |
| 2014-05-27 11:55:56 | Yuki Kajiura | 1 | 5 |
| 2014-05-27 12:00:16 | Yuki Kajiura | 1 | 6 |
| 2014-05-27 12:04:23 | Yuki Kajiura | 1 | 7 |
ggplot(data = cumulative_artists, aes(x = listened_at, y = listens, group = artist_name, colour = artist_name)) +
ggtitle("Cumulative Listens of Top 10 Artists Over Time") +
xlab("# of listens") +
ylab("Artist") +
labs(colour = "Artist") +
geom_line(size = 1) +
scale_color_brewer(palette = "Paired") +
theme(legend.position = "bottom", legend.box = "vertical") +
guides(colour = guide_legend(nrow = 2, byrow = TRUE))
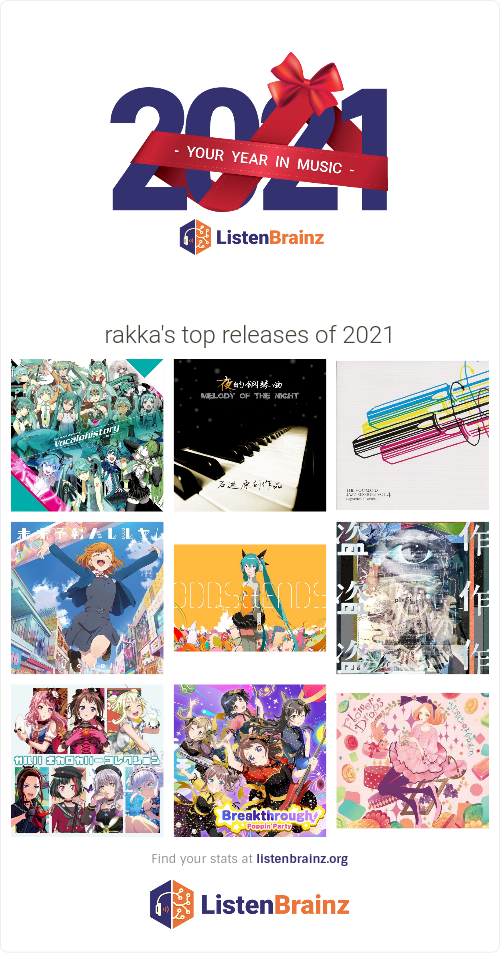
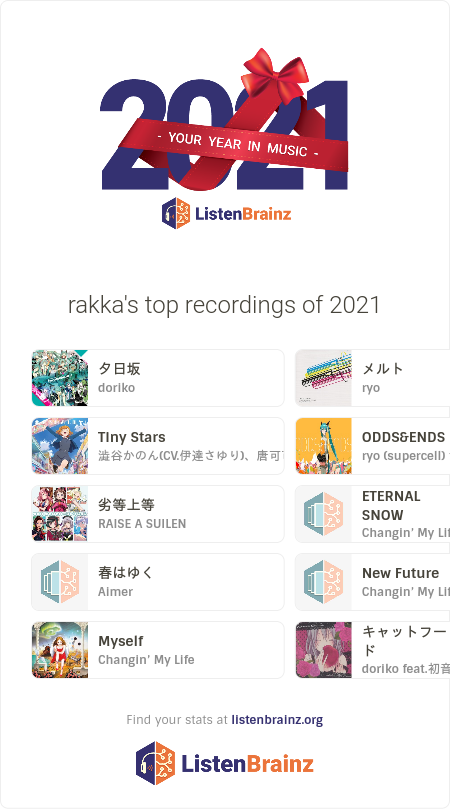
ListenBrainz Analysis
Added 2021-12-16.
It turns out ListenBrainz does its own Year in Music, some of which is attached below. They don’t do data cleaning, presumably because what you should do is go update the ListenBrainz database and retag your library (which I should be better about doing, for sure).